Letzte Woche hat Salesforce Headless 360 als seine "ambitionierteste Architektur-Transformation seit 27 Jahren" angekündigt. Das Versprechen: die gesamte Salesforce-Plattform als APIs, MCP-Tools und CLI-Befehle verfügbar machen, damit KI-Agenten Geschäftsprozesse ausführen können, ohne jemals einen Browser zu öffnen. Die Ära der Agenten ist da. Man muss nur noch verbinden.
Ich habe genug Enterprise-Systeme von innen gesehen, um zu erklären, was als Nächstes passiert.
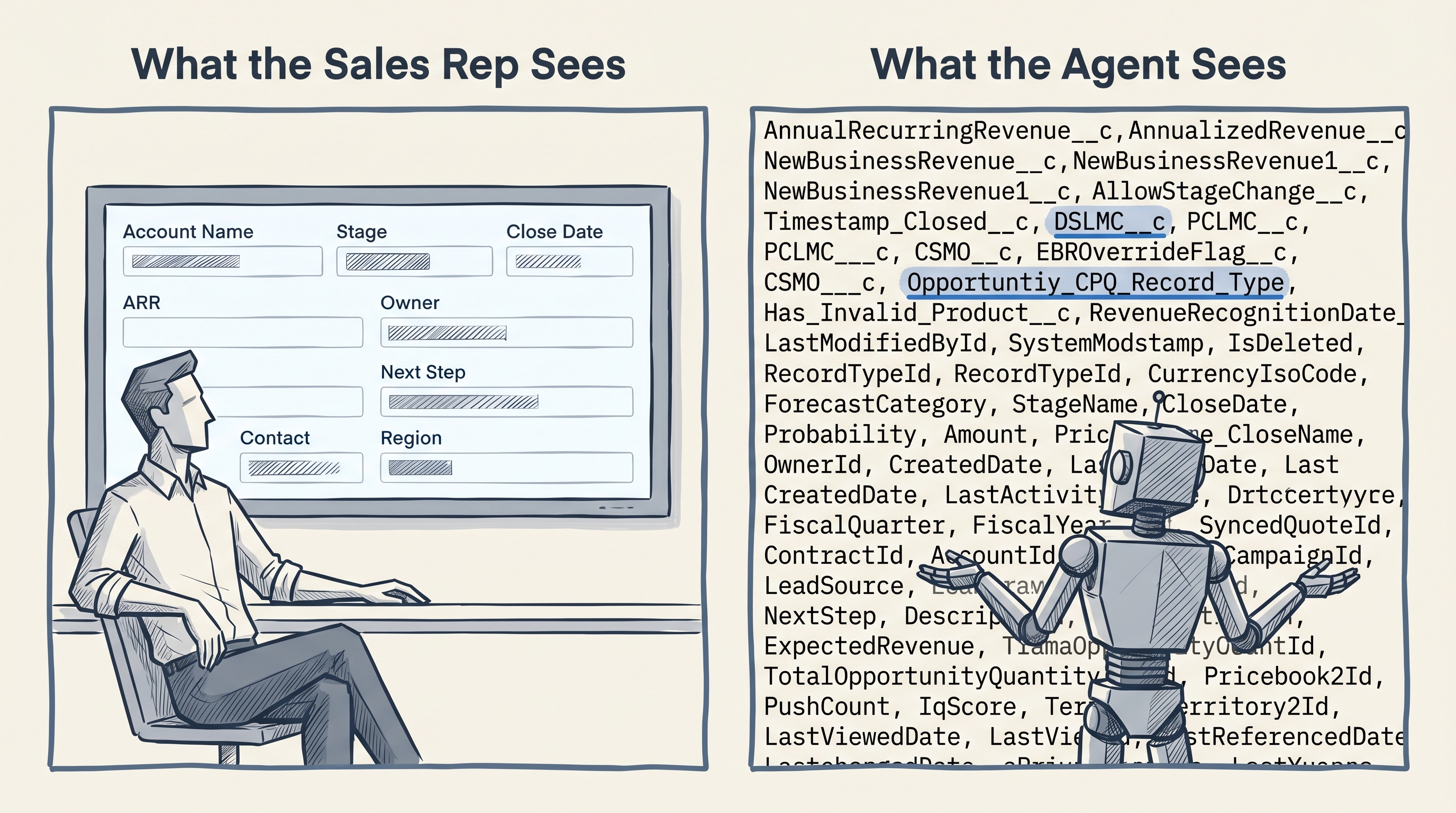
Der Agent verbindet sich. In Salesforce sieht er 74 Custom Fields am Opportunity-Objekt, zusätzlich zu allen Standardfeldern. Er sieht AnnualRecurringRevenue__c und AnnualizedRevenue__c nebeneinander. Eines ist die ARR-Zahl für die Pipeline. Das andere schließt Nicht-Abo-Produkte ein, ist also ein grundlegend anderes betriebswirtschaftliches Konzept, nicht nur eine Formatierungsvariante. Ohne diesen Kontext, irgendwo aufgeschrieben, wählt der Agent eines. Er sieht NewBusinessRevenue__c und NewBusinessRevenue1__c, das "1" ohne Erklärung. Er sieht DSLMC__c, PCLMC__c, CSMO__c: interne Abkürzungen, die jemandem etwas bedeuten, der schon lange genug im Unternehmen ist, und allem anderen gar nichts.
Headless 360 ist eine breitere Tür in dasselbe Labyrinth. Das sagt gerade niemand im LinkedIn-Feed.
Und Salesforce ist nur das aktuell deutlichste Beispiel. Dasselbe Muster zeigt sich in SAP, ServiceNow, Legacy-ERPs und selbst gebauten CRMs. Jedes System, das über Jahre stark customisiert wurde (von Menschen, die es über eine für Menschen entwickelte Oberfläche navigiert haben), trägt dasselbe strukturelle Problem. API-first-Zugang löst es nicht. Er macht es nur zugänglicher.
Zwei Tracks, eine Wand
Die meisten Unternehmen fahren gerade zwei KI-Experimente parallel — und behandeln sie als getrennte Probleme.
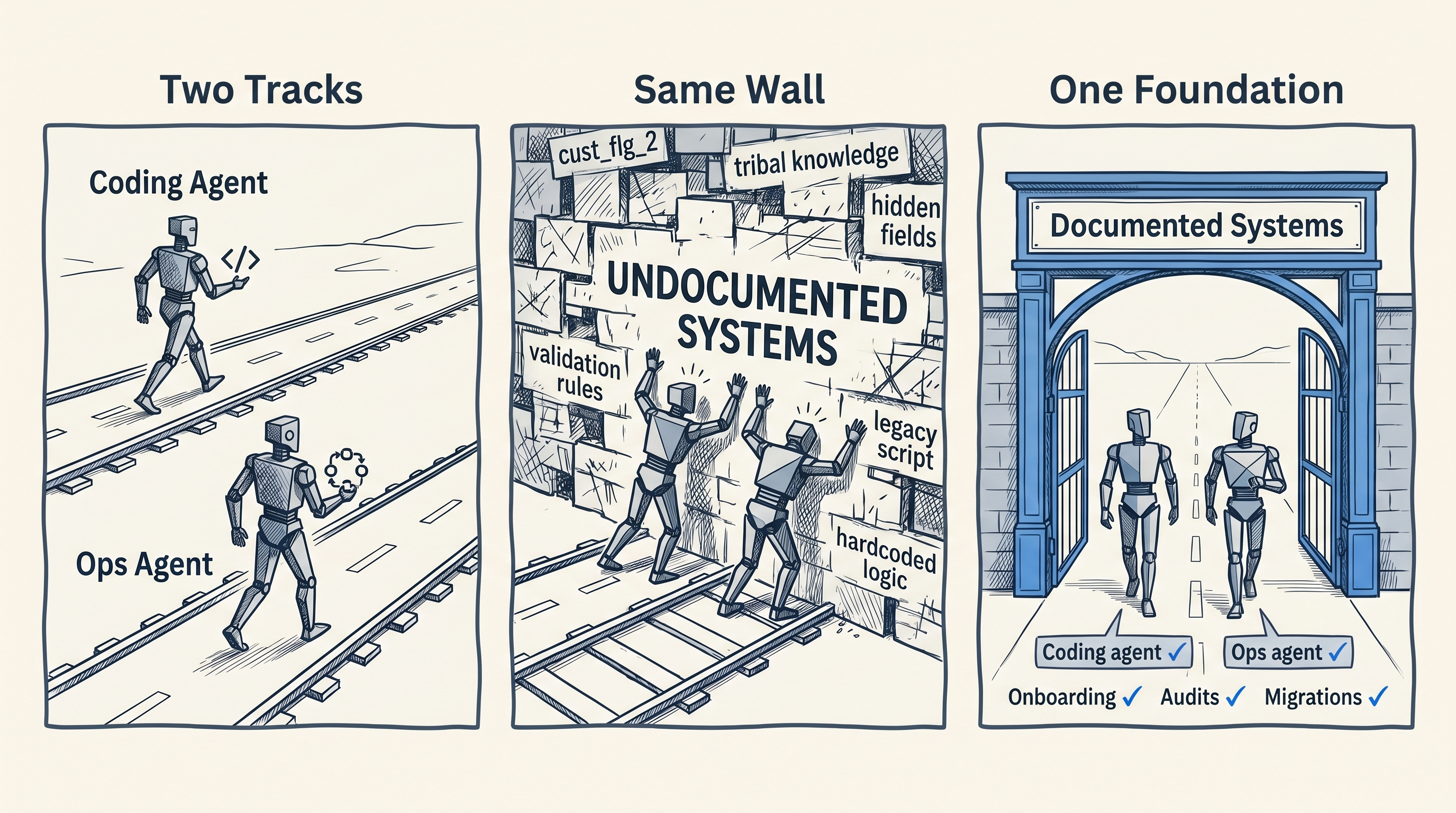
Track eins: Agentic Development. Engineering-Teams nutzen Coding Agents (Cursor, Claude Code, GitHub Copilot) um Features schneller zu liefern, Bugs zu beheben und bestehende Systeme zu erweitern.
Track zwei: Agentic Operations. Operations-Teams verbinden KI-Agenten mit Geschäftssystemen (Salesforce, ServiceNow, SAP) um Prozesse zu automatisieren, Anfragen zu routen, Datensätze zu aktualisieren und Workflows auszulösen.
Beide Tracks stoßen gegen eine Wand. Die zeigt sich meistens in der zweiten Woche eines Pilots, nachdem das initiale Setup abgeschlossen ist und der Agent auf die Teile des Systems trifft, die echten Kontext erfordern. In der ersten Woche bearbeitet der Agent die einfachen Fälle: die sauber benannten Felder, die Prozesse, die so gebaut wurden, dass sie selbsterklärend sind. In Woche zwei beginnt die Komplexität: die Ausnahmen, die Felder, die sich von ihrer ursprünglichen Bedeutung entfernt haben, die Geschäftslogik, die nie aufgeschrieben wurde, weil die Leute, die sie gebaut haben, noch im Unternehmen sind.
Der Coding Agent produziert Code, der kompiliert, läuft und falsch ist. Nicht offensichtlich falsch; subtil falsch. Die Profit-Center-Allokationslogik ist ein gutes Beispiel. Sie begann als einfache Regel. Über drei Jahre, während das Unternehmen wuchs und Ausnahmen sich häuften, wurde sie immer komplexer, ohne je neu gestaltet oder formal neu definiert zu werden. Die Logik lebt im Custom Code, der um das ursprüngliche Feature herum gewachsen ist, und teilweise in den Köpfen der Leute, die über die Jahre dazu beigetragen haben. Ein Coding Agent, der dieses System erweitern will, hat keine Möglichkeit zu wissen, wo die formalen Regeln enden und die undokumentierten Ausnahmen beginnen. Also macht er plausibel aussehende Änderungen, die Constraints verletzen, die niemand aufgeschrieben hat.
Der Operations Agent stößt von der anderen Seite auf dasselbe Problem. Er traversiert die API, findet die Felder und befüllt die falschen, nicht weil das Modell schlecht ist, sondern weil die Bedeutung dieser Felder von Kontext abhängt, der in Gesprächen, in Onboarding-Decks, im institutionellen Gedächtnis der Leute existiert, die lange genug dabei sind. Wenn ein Unternehmen "Revenue" sagt, meint es vielleicht speziell den wiederkehrenden Umsatz, die Hauptzahl, die alle tracken. Wenn ein Sales Manager "meine Kunden" sagt, meint er die Accounts, die er ownt. Wenn ein Customer-Success-Manager dasselbe sagt, bezieht er sich auf eine andere Feldbeziehung. Diese Unterschiede lassen das Unternehmen funktionieren. Im Schema existieren sie nicht.
Die Reaktion des Teams ist in beiden Fällen fast immer dieselbe: KI funktioniert nicht.
Das ist meistens die falsche Diagnose.
Warum die meisten Enterprise-KI-Piloten scheitern
Was passiert, ist Kontext-Entzug. Der Agent hat keinen Zugang zu dem Wissen, das er braucht, um korrekt zu handeln. In den meisten Enterprise-Systemen existiert dieses Wissen nirgendwo, wo ein Agent es finden könnte — es existiert in Menschen, oder in High-Level-Onboarding-Präsentationen, die nie dazu gedacht waren, maschinenlesbar zu sein.
Bis Mitte 2025 hatte Gartner festgestellt, dass Datenqualitätsprobleme als größtes Hindernis für KI-Adoption in einem einzigen Jahr fast verdreifacht hatten, von 19% der Organisationen in 2024 auf 44% in 2025. MIT's NANDA Initiative dokumentierte, dass 95% der Enterprise-KI-Piloten keinen messbaren P&L-Impact lieferten. 60% der KI-Projekte ohne KI-bereite Daten wurden für Aufgabe bis 2026 prognostiziert. Je mehr Organisationen von Piloten zu Produktion wechseln, desto schwerer wird das Dokumentationsgap zu ignorieren, nicht leichter.
In jedem Fall führt das Scheitern auf dieselbe Ursache zurück: Das System wurde nie für etwas anderes gebaut als für die Menschen, die jahrelang gelernt hatten, es zu navigieren.
Und fast niemand bemerkt, dass das Lesbarkeits-Problem des Coding Agents und das Lesbarkeits-Problem des Operations Agents dasselbe Problem sind. Organisationen behandeln sie als getrennte Initiativen mit getrennten Budgets und getrennten Vendoren. Die Lösung für eines ist die Lösung für das andere.
Was Agenten tatsächlich brauchen
Menschen navigieren unordentliche Systeme durch Gefühl — und indem sie fragen, wenn sie nicht weiterkommen. Ein Engineer, der nicht weiß, was Profit_Center_c__c tut (im Unterschied zu Profit_Center__c), kann die Person finden, die es weiß. Ein KI-Agent kann nicht fragen. Er sieht das Feld, zieht eine Schlussfolgerung, und handelt danach.
Agenten arbeiten mit dem, was sie sehen können. Nichts weiter. Ein System, in dem Namen bedeuten, was sie sagen, und die Geschäftsregeln irgendwo auffindbar aufgeschrieben sind: das funktioniert. Ein System, das zwölf Jahre Kontext zum Navigieren erfordert: darin verirren sich Agenten, zuversichtlich.
In der Datentechnik hat dieses Problem bereits einen Namen und eine Lösung: den Semantic Layer. Ein Semantic Layer sitzt zwischen Rohdaten (unordentlich, inkonsistent benannt, voller Legacy-Artefakte) und den Werkzeugen, die sie konsumieren, und bietet eine Übersetzungsschicht mit bedeutungsvollen Namen und kodierter Geschäftslogik.
Was das in der Praxis bedeutet: Dasselbe Revenue-Konzept kann in drei Währungsvarianten mit unterschiedlichen Wechselkursannahmen existieren. Ein Status-Feld kann Werte tragen, die ähnlich aussehen, aber komplett unterschiedliche Downstream-Prozesse auslösen. Jedes braucht eine Klartextbeschreibung, was es tatsächlich bedeutet und wann es zu verwenden ist. Das ist der Semantic Layer für einen Operations Agent.
Für Codebasen ist das Äquivalent eine strukturierte Dokumentation: Architektur-Überblicke, Erklärungen auf Modul-Ebene, Hinweise darauf, warum nicht-offensichtliche Entscheidungen getroffen wurden. Nicht ein einzelnes flaches Dokument, sondern so organisiert, dass ein Agent den richtigen Kontext für die Aufgabe abrufen kann, an der er gerade arbeitet. Was beim Treffen einer Entscheidung nicht offensichtlich war, ist für etwas, das den Code drei Jahre später liest, vollständig undurchsichtig.
Beide lösen dasselbe Problem aus verschiedenen Winkeln: Sie machen ein System navigierbar für etwas, das keinen Kollegen fragen kann.
Warum Headless 360 das nicht ändert
Zurück zu Salesforce. Die Coverage von Headless 360 war fast ausschließlich über das, was es ermöglicht: Agenten, die Geschäftsprozesse in großem Maßstab ausführen, die gesamte Plattform via API und MCP-Tools zugänglich. Was keine davon anspricht, ist der Zustand der Org darunter.
Salesforce macht Customization einfach. Über Jahre war die primäre Schnittstelle die UI: Page Layouts, sorgfältig kuratiert, um jeder User-Rolle die 20 bis 30 relevanten Felder zu zeigen. Felder, die nicht benötigt wurden, wurden aus Layouts ausgeblendet. Probleme wurden gelöst, indem Felder, Validierungsregeln und Automatisierungs-Flows hinzugefügt wurden. Akquisitionen brachten Objekte mit Namen aus dem übernommenen Unternehmen. Alte Felder wurden aus Layouts entfernt, wenn sie Verwirrung verursachten, blieben aber in der Datenbank, weiterhin via API zugänglich, weiterhin mit mehrdeutigen Namen und undefiniertem Verhalten.
Das Ergebnis ist ein System, das funktioniert, weil Menschen es durch die UI navigieren. Das Page Layout filtert das Rauschen. Das institutionelle Wissen füllt aus, was das Layout nicht erklärt.
Agenten nutzen die API. Die API filtert nichts. Nehmen wir eine typische reife Salesforce-Org: das Opportunity-Objekt allein trägt 70+ Custom Fields. Ein Sales Rep sieht davon im Tagesgeschäft etwa 25. Ein Agent mit API-Zugang sieht alle, einschließlich der, die aus Layouts entfernt wurden, weil sie Verwirrung verursachten, der, die zweimal im Jahr in Ausnahme-Fällen genutzt werden, und der, deren Namen von ihrem tatsächlichen Inhalt abgewichen sind, als sich die Geschäftslogik änderte, aber niemand das Feld umbenannt hat.
Validierungsregeln fügen eine weitere Schicht hinzu. Eine typische Org erzwingt Dinge wie: Wahrscheinlichkeit muss exakt zur Stage passen, ein bestimmtes Flag muss false sein, bevor eine Opportunity geschlossen werden kann, Stage-Änderungen werden nach Booking-Approval blockiert. Jede Regel kodiert eine Geschäftsentscheidung. Keine davon ist in Klarsprache dokumentiert, irgendwo, wo ein Agent sie abrufen könnte. Wenn ein Agent auf sie trifft, bekommt er kryptische API-Fehler, und versucht es möglicherweise mit anderen Werten erneut, macht Partial Writes, oder liefert eine Fehlermeldung, die ohne den Kontext zur Interpretation keinen Sinn ergibt.
Headless 360 macht das Bauen von Agent-Integrationen erheblich einfacher. Es macht die Org nicht lesbarer. Eine vollständig customisierte Salesforce-Org mit zwölf Jahren akkumulierter Feld-Naming-Schulden und Validierungsregeln, die Stammeswissen kodieren, wird nicht agenten-bereit, weil die API-Oberfläche sich erweitert hat. Der Agent bekommt eine bessere Eingangstür zu einem Gebäude, das er immer noch nicht navigieren kann.
Dasselbe gilt für jedes andere Enterprise-System, das gerade eine "agent-ready" API-Schicht launcht, während das Datenmodell darunter undokumentiert bleibt. API-first öffnet die Tür. Es räumt den Raum nicht auf.
Was tatsächlich funktioniert
Die Frage ist nicht ob man das angehen soll, sondern was zuerst.
Der häufigste Fehler ist den KI-Pilot als Startpunkt zu behandeln. Der Pilot legt das Lesbarkeits-Problem offen, aber zu diesem Zeitpunkt hat man Monate dafür aufgewendet, das Team hat den Schluss gezogen, dass KI für diesen Use Case nicht funktioniert, und das zugrunde liegende Problem ist immer noch nicht behoben. Die Legibility-Arbeit muss zuerst passieren, begrenzt auf den Bereich, den der Agent tatsächlich berühren wird.
Wir haben unsere Approval Flows neu dokumentiert. Kein umfassendes Dokumentationsprojekt, sondern eine gezielte Anstrengung an einem spezifischen Satz von Prozessen, die wir erweitern wollten. Wir haben gemappt, was die Flows tatsächlich tun, es mit dem verglichen, was das Unternehmen erwartet, und Lücken gefunden. Einige entpuppten sich als echte Prozess-Bugs, die Menschen jahrelang intuitiv umgangen hatten, ohne sie zu melden. Wir haben die behoben. Dann haben wir einen Development Agent genutzt, um die Approval-Logik auf dem jetzt dokumentierten Fundament zu erweitern. Der Agent hatte etwas Lesbares zum Navigieren, und es hat funktioniert.
Die meisten Organisationen machen es in umgekehrter Reihenfolge: zuerst der Pilot, dann die Wand, dann der Versuch, die Dokumentation zu reparieren, während das Projekt bereits scheitert.
Der beste Startpunkt ist dort, wo das Fundament bereits solide ist, oder wo von Grund auf gebaut wird. Wir haben früh einen KI-Agenten an unsere Case-Creation und -Klassifikation angebunden — es hat funktioniert, weil der Prozess gut definiert war, die Inputs strukturiert waren und die Geschäftslogik klar war. Wir haben einen agentengesteuerten Outreach-Workflow für Long-Tail-Leads von Grund auf gebaut, was es erlaubte, ihn von Anfang an lesbar zu gestalten. Keiner dieser Fälle war ein Kern-Geschäftsprozess mit zwölf Jahren akkumulierter Komplexität.
Die Prozesse mit dem höchsten ROI (die mit der meisten Komplexität, dem meisten Stammeswissen, dem höchsten Einsatz) sind genau die, die die meisten Organisationen zuerst automatisieren wollen, weil die Zahlen am größten aussehen. Sie sind auch die, die am dringendsten die Dokumentationsarbeit brauchen, bevor der Agent sie berührt. Dieser Mismatch ist, wo die meisten Piloten scheitern.
Der Compound Return
Das ist teils ein Sequenzierungs-Problem und teils ein Framing-Problem. Die Dokumentations-Investition wird als Overhead für das KI-Projekt gerahmt. Das ist sie nicht, und das ist wichtig dafür, wie sie intern gerechtfertigt wird.
Dokumentation, die für einen Agenten gebaut wurde, dient auch Onboarding, Audits, Daten-Migrationen und den Integrationen, um die das Engineering-Team seit Jahren herumnavigiert. Wenn der Pilot erfolgreich ist, steht das Fundament für den nächsten. Wenn nicht, bleibt Dokumentation, die ohnehin längst überfällig war. Das Pitch an die Führungsebene lautet nicht "Finanziert einen KI-Pilot." Es lautet: "Finanziert Dokumentationsarbeit, die seit Jahren überfällig ist — KI macht sie jetzt dringend."
KI lässt sich dabei nutzen, um die Dokumentation selbst zu erstellen. Schema-Dokumentation, die das Data-Team bereits für Reporting pflegt, ist ein Startpunkt; ein Sprachmodell kann sie in die Klartextbeschreibungen übersetzen, die ein Agent braucht. Bestehende Prozessdokumentation, auch wenn sie unvollständig ist, kann von einem Coding Agent zu Lücken weiterentwickelt werden. Der Schritt, der nicht übersprungen werden kann, ist die Validierung: jemand, der das System kennt und bestätigt, dass das Aufgeschriebene dem entspricht, was das System tatsächlich tut. Das kann nicht an ein Modell delegiert werden. Die Ausarbeitung drum herum schon.
Wo anfangen
Die Coding-Agent-Piloten des Engineering-Teams und die Prozessautomatisierungs-Piloten des Operations-Teams stoßen gegen dieselbe Wand. Die meisten Organisationen behandeln sie als verschiedene Probleme: verschiedene Budgetlinien, verschiedene Vendoren, verschiedene Post-Mortems, wenn sie scheitern.
Sie teilen eine Ursache. Es ist dieselbe Arbeit. Eine Codebasis für den Coding Agent zu dokumentieren, macht sie auch für den Operations Agent lesbar, der in diese Systeme hineinkommunizieren muss. Das Salesforce-Schema für den Operations Agent aufzuräumen, gibt Coding Agents gleichzeitig ein sauberes Fundament, auf dem sie skalierbar aufbauen können. Eine Investition, die sich auszahlt, egal ob Coding Agents, Operations Agents oder beide im Einsatz sind, und Wert für Onboarding, Audits und Migrationen liefert, unabhängig davon, ob die KI-Piloten erfolgreich sind.
Die Technologie ist bereit. Die Frage ist, ob die Systeme es sind.
Das Fundament nicht überspringen. Den Bereich wählen, in dem KI operieren soll, und einen Dokumentationsaufwand beauftragen, der speziell auf diesen Bereich begrenzt ist — die Prozesse, die der Agent ausführen wird, die Felder, die er lesen und schreiben wird, die Geschäftsregeln, die er respektieren muss. Ein begrenzter Semantic Layer für einen definierten Satz von Objekten ist typischerweise eine Sache von Wochen, nicht Monaten. Kein Transformationsprogramm, sondern eine gezielte Dokumentations- und Validierungsarbeit mit definiertem Scope.
Bevor man ihn von Grund auf in Auftrag gibt, lohnt sich die interne Nachfrage. Analytics- oder Data-Engineering-Teams stoßen häufig auf dieselbe Lesbarkeits-Wand beim Erstellen von Reports und haben als Ergebnis ihre eigenen Schema-Wörterbücher erstellt. Wenn diese Arbeit irgendwo in der Organisation existiert, ist sie der Startpunkt, nicht das fertige Produkt, aber ein Fundament, das den Aufwand erheblich reduziert.
Dann den Agenten einführen.
Wer als RevOps- oder IT-Lead dieses Problem erkennt, aber nicht das Budget kontrolliert, um es zu lösen: Das ist das Argument, das nach oben getragen werden sollte. Die Dokumentationsarbeit ist aus eigenen Gründen gerechtfertigt — Onboarding, Audits, Migrationen — unabhängig von KI. Der KI-Fall macht sie dringend. Diese Kombination ist einfacher zu finanzieren als "Wir müssen das CRM aufräumen, bevor der Pilot startet."
Eigene AI-Infrastruktur aufbauen?
Ich helfe Teams beim Design und der Implementierung von AI-nativen Systemen.
Kontakt aufnehmen